
强化学习的迅速发展并不意味着深度学习的退出,两者的关系像是倚天剑与屠龙刀:强化学习给出了要实现的目标,深度学习则定义了实现目标的方法,两者融合方能得到通向通用人工智能的秘笈。目前最新的深度强化学习算法是Deep Mind公司于2016年11月提出的UNREAL算法(Unsupervised Reinforcement and Auxiliary Learning),这套算法将强化学习和无监督式学习结合起来,并以辅助任务对算法进行改进,是目前效果最好的深度强化学习算法。
图9-2 强化学习的网络结构
和强化学习的概念一样,UNREAL算法的基本思想也借鉴了人类的学习方式。人在完成一项任务的时候,往往会通过并行使用多种辅助任务来实现。一个简单的例子就是需要在微信点赞的时候,我们一方面会给好友群发点赞的消息,也会转发到朋友圈中请别人帮忙扩散,这也正是UNREAL算法的核心。通过设置多个辅助任务同时训练单个行动-评判网络,UNREAL算法可以在加快学习速度的同时进一步提升性能。
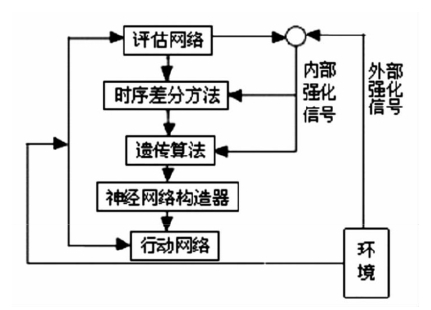
UNREAL算法中的辅助任务可以分为三类:控制任务、回馈预测任务和价值迭代任务。具体到图像处理的场景下,控制任务包括像素控制和隐藏层激活控制。像素控制是指控制输入图像的变化使得输出图像的变化最大,因为输出图像的剧烈变化意味着智能体在执行重要的环节,因而通过控制图像的变化能够改善动作的选择。隐藏层激活控制则控制隐藏层神经元的激活过程,尽可能激活量更多的神经元,这就如同大脑开发的程度越高,人就会变得越聪明,也就能够做出更好的选择。回馈预测任务针对的是回馈值无法取得的情况,如果神经网络能够预测回馈值,就会带来更好的表达能力。价值迭代任务的作用是使用历史信息求解损失函数,对价值网络中神经元的参数进行更新,进一步提升算法的训练速度。值得注意的是,虽然UNREAL算法通过不同任务的并行训练来提升神经网络的能力,但其样本数量并未增加,而是在保持原有样本数据不变的情况下,通过对已有数据更加充分的挖掘与利用实现对算法进行提升。
强化学习的强大能来源于两个方面:使用样本来优化行为,使用函数近似来描述复杂的环境。它们使得强化学习可以使用在更加复杂的环境之中。在很多问题中,模型的环境无法确定,或是根本不存在解析解,所有的知识仅限于给出环境的模拟模型。在这种情况下,从环境中获取信息的唯一办法是和它互动。这些问题都可以通过引入强化学习来解决。
强化学习的一个重要应用领域就是实现目标驱动的视觉导航,简单来说就是让机器人具备人类的视觉功能。移动机器人的导航问题已有超过半个世纪的历史,其研究内容是实现移动机器人在未知环境中实现从起始位置到目标位置的避障行进。然而在未知环境中,状态空间表现为一个无限维度的连续空间,这让传统的查表类方法不再适用。在这种复杂的条件下,神经网络结合深度强化学习成为解决机器人导航问题的不二法门。
强化学习的主体与环境基于离散的时间步长相作用。其目标是得到尽可能多的奖励。主体选择的动作是其历史的函数,它也可以选择随机的动作。将这个主体的表现和自始至终以最优方式行动的主体相比较,它们之间的行动差异产生了“悔过”的概念。如果要接近最优的方案来行动,主体就要避免跌入“鼠目寸光”的陷阱,必须根据它的长时间行动序列进行推理。因此,强化学习更擅长解决包含长期反馈的问题。
2016年9月,美国斯坦福大学的李飞飞研究组发表了论文《以深度强化学习实现室内场景下的目标驱动视觉导航》,使机器人能够根据实时环境与目标达到指令所指示的任务。论文的作者们使用的是从虚拟迁移到现实的思想:让机器人在高度仿真的环境中执行训练,掌握技能后再迁移到真实场景中,并取得了良好的效果。这将给未来家用机器人的发展带来革命性的变化:连门槛都迈不过去的笨笨的扫地机器人将会成为历史,能够端茶倒水、开门关灯的机器管家即将来临。
一个基本的强化学习模型至少包括5个组成部分:(1)环境状态的集合;(2)主体动作的集合;(3)在状态之间转换的规则;(4)规定转换后“即时奖励”的规则;(5)描述主体能够观察到什么的规则。在增强学习中,规则往往是随机的,主体可以观察到的内容是即时奖励和最后一次转换。在许多模型中,主体被假设为可以观察现有的环境状态,这种情况称为完全可观测,否则则称为部分可观测。有时,主体被允许的动作也会受到限制,就如同我们能支配的财富数目不能超过银行存款的余额。
机器人导航这个任务在传统的机器人学中是这样实现的:首先要完成对未知环境的建模,这个步骤可以通过机器人上的传感设备采集空间信息来实现;建模完成后就要构建语义地图,也就是在空间模型中为各种物品添加语义信息——这个是椅子,那个是冰箱,诸如此类;接下来就要基于语义地图执行路径规划,机器人只需要根据规划出来的最优路径行进就可以了。当然,我们的描述只用了寥寥百余字,但这百余字背后是百万行数量级的复杂代码,其实现实过程非常复杂。
与传统意义上的深度学习不同,强化学习是基于环境反馈实现决策制定的通用框架,根据不断试错而得到的奖励或者惩罚实现对趋利决策信念的不断增强,强调在与环境的交互过程中实现学习。强化学习与标准的监督式学习之间的区别则在于它并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索未知领域和遵从已有知识之间找到平衡。
好在强化学习的出现改变了这一切。论文中实现导航的方式就是将目标作为输入,让机器人自行寻找目标,深度强化学习则被应用在机器人具体的训练过程中(具体的技术细节本书受主题限制不做解释,感兴趣的读者可自行阅读论文)。与传统的机器人学方法相比,由于神经网络具有通用性,因此训练出来的机器人掌握的是通用的方法——学会了找椅子,也就学会了找冰箱、台灯、水壶……当然,机器人并没有记住物体的位置,更不知道房屋的结构,但它能够通过不断试错自行寻找通向每个物体的路径,这也暗合了我国的那句古话:“授人以鱼,不如授人以渔”。
强化学习(Reinforcement Learning)是近年来深度学习领域迅猛发展起来的一个分支,目的是解决计算机从感知到决策控制的问题,从而实现通用人工智能。具体来说,强化学习是通过智能体在客体环境中采取某种行动,以取得最大化的预期利益。这一概念的灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。这个方法在人类的知识获取和技能习得中已经得到广泛应用,在诸如博弈论、控制论、运筹学、信息论、仿真优化方法、多主体系统学习、群体智能、统计学以及遗传算法等其他学科中也有大量的使用。